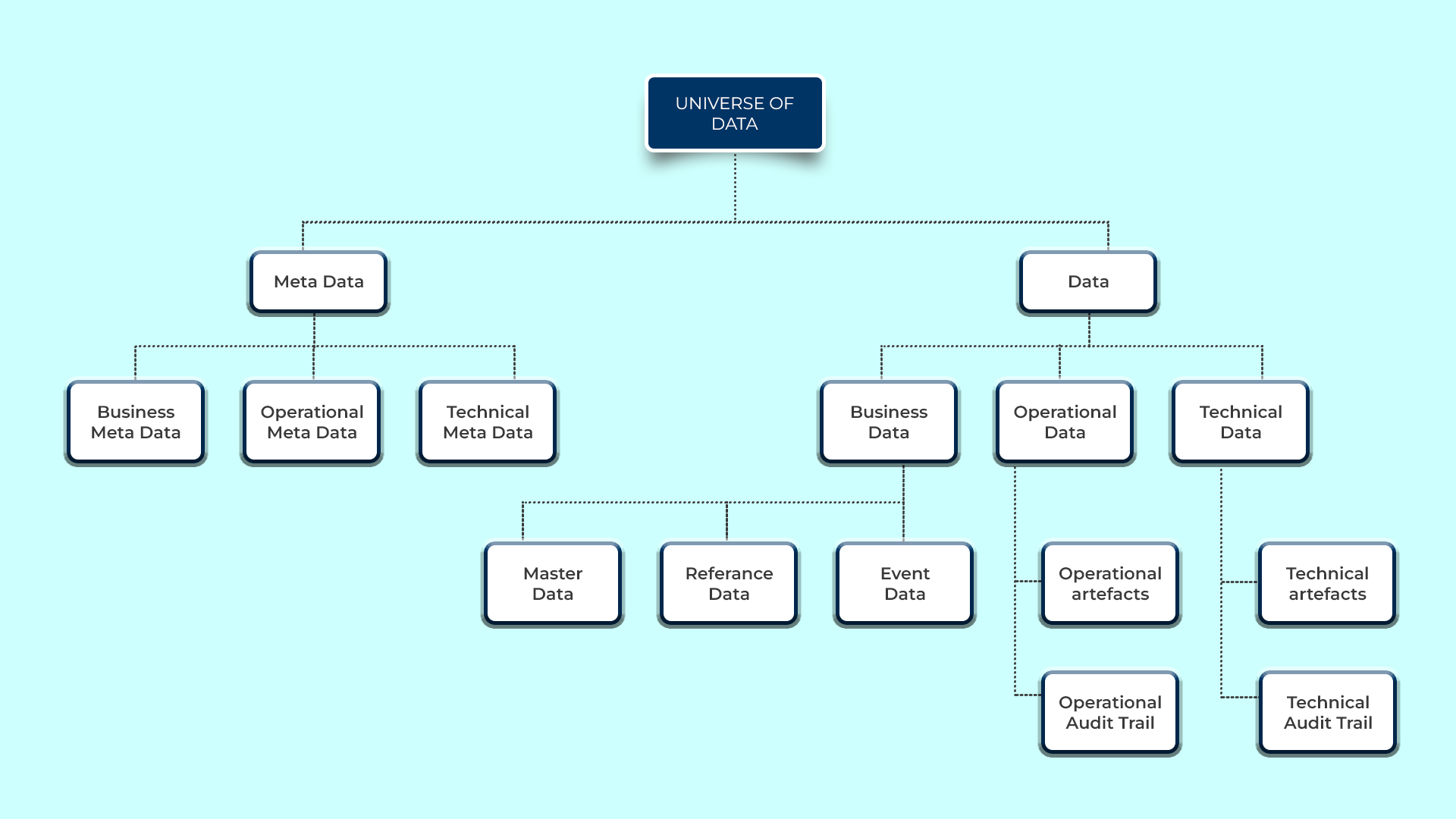
A common conversation these days is “Data management activities take too long”. To source data, cleanse it, integrate it, and then make it available for consumption is time-consuming to meet analytical needs. Many organisations procure a Bigdata platform, source data into the Bigdata platform, and let data scientists have access to the data and go about building analytic solutions. Most organizations that jumped onto this bandwagon soon realized that their ROI, which initially showed signs of being ahead of the curve, never met their targets. According to Forbes, data scientists spend around 80% of their time on preparing and managing data for analysis. 76% of data scientists also view data preparation as the least enjoyable part of their work On the otherhand, if organisations went back to the wild-wild west scenario, where analytic solutions are created with scant regard to Data Management, it will only lead to more data quality issues, proliferation of data orphans and turn the vision of a data-driven organisation into data swamp reality. It is worth looking at a real life example. An organisation that rents vending machines wanted to build an analytical model to efficiently plan when vehicles should go to collect cash and replenish merchandise. The project team felt it is time-consuming and unnecessary for their use case to meet all the pre-requisites prescribed by the Data Management office. They chose not to address Reference Data and Master Data concerns raised because it would take a long time. The project rolled out the analytic model and saw their efficiency jump 50% in the first year. However, in the second year, they only saw a 7% increase in their efficiency. In fact, on certain months they did worse than the median. Upon doing root cause analysis it was discovered that their process for maintaining vending machines Master Data was fraught with inconsistencies. It was manual and produced erroneous data. There were instances where vehicles turned up to replenish only to find there were no machines at the specified location. In some cases, they did not have the correct vending machine model information. As a result, they could not replenish fully. They had to do an extra trip to replenish. In the end, it was concluded that they can’t reach their target of 90% efficiency unless they deal with Master and Reference data strategically. And they would reach their 90% efficiency 2 years later and a few hundred 1000 dollars over what was budgeted.